About
I'm a 2nd year Ph.D. student in Computer Science at University of Illinois Urbana-Champaign supervised by Prof. Saurabh Gupta.
Before that, I earned my bachelor degree at ACM Honors Class, Shanghai Jiao Tong University and I was privileged to delve into the application of Reinforcement Learning in Quadruped Robot's locomotion while collaborating with the SJTU APEX lab under the guidance of Prof. Weinan Zhang.
During my senior year, I was fortunate to work with Prof. Xiaolong Wang at UCSD Wang Lab as a research intern. During my time there, I also had the opportunity to collaborate closely with Prof. David Held.
My research interests lie in Reinforcement Learning, Robot Learning, Computer Vision and Control Theory.
If you are interested in my work, feel free to contact me for further discussions or potential collaborations.

ContactMimic: Humanoid Object Interaction via Contact Control
Xinyao Li*, Xialin He*, Runpei Dong, Saurabh Gupta
arXiv2026
A learning framework that tracks explicit part-level binary contact commands alongside keypoint trajectories, decoupling contact behavior from keypoint geometry for precise and controllable humanoid-object interaction.

ULTRA: Unified Multimodal Control for Autonomous Humanoid Whole-Body Loco-Manipulation
Xialin He*, Sirui Xu*, Xinyao Li, Runpei Dong, Liuyu Bian, Yu-Xiong Wang, Liang-Yan Gui
IROS2026
A unified framework for autonomous humanoid whole-body loco-manipulation combining physics-driven motion retargeting with multimodal control.


Learning Smooth Humanoid Locomotion through Lipschitz-Constrained Policies
Zixuan Chen*, Xialin He*, Yen-Jen Wang*, Qiayuan Liao, Yanjie Ze, Zhongyu Li, S. Shankar Sastry, Jiajun Wu, Koushil Sreenath, Saurabh Gupta, Xue Bin Peng
IROS2025 (Oral)
Lipschitz-Constrained Policies (LCP) for smooth locomotion in legged robots, eliminating non-differentiable smoothing techniques.

OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning
Tairan He*, Zhengyi Luo*, Xialin He*, Wenli Xiao, Chong Zhang, Weinan Zhang, Kris Kitani, Changliu Liu, Guanya Shi
CoRL2024
A learning-based system for whole-body humanoid teleoperation and autonomy using kinematic pose as a universal control interface.



InterPrior: Scaling Generative Control for Physics-Based Human-Object Interactions
Sirui Xu, Samuel Schulter, Morteza Ziyadi, Xialin He, Xiaohan Fei, Yu-Xiong Wang, Liang-Yan Gui
CVPR2026
A scalable generative controller for humanoid human-object interactions via large-scale imitation distillation.

SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Zekun Qi*, Wenyao Zhang*, Yufei Ding*, Runpei Dong, Xinqiang Yu, Jingwen Li, Lingyun Xu, Baoyu Li, Xialin He, Guofan Fan, Jiazhao Zhang, Jiawei He, Jiayuan Gu, Xin Jin, Kaisheng Ma, Zhizheng Zhang, He Wang, Li Yi
NeurIPS2025 (Spotlight)
Semantic orientation using natural language to describe object orientations for improved robotic manipulation.
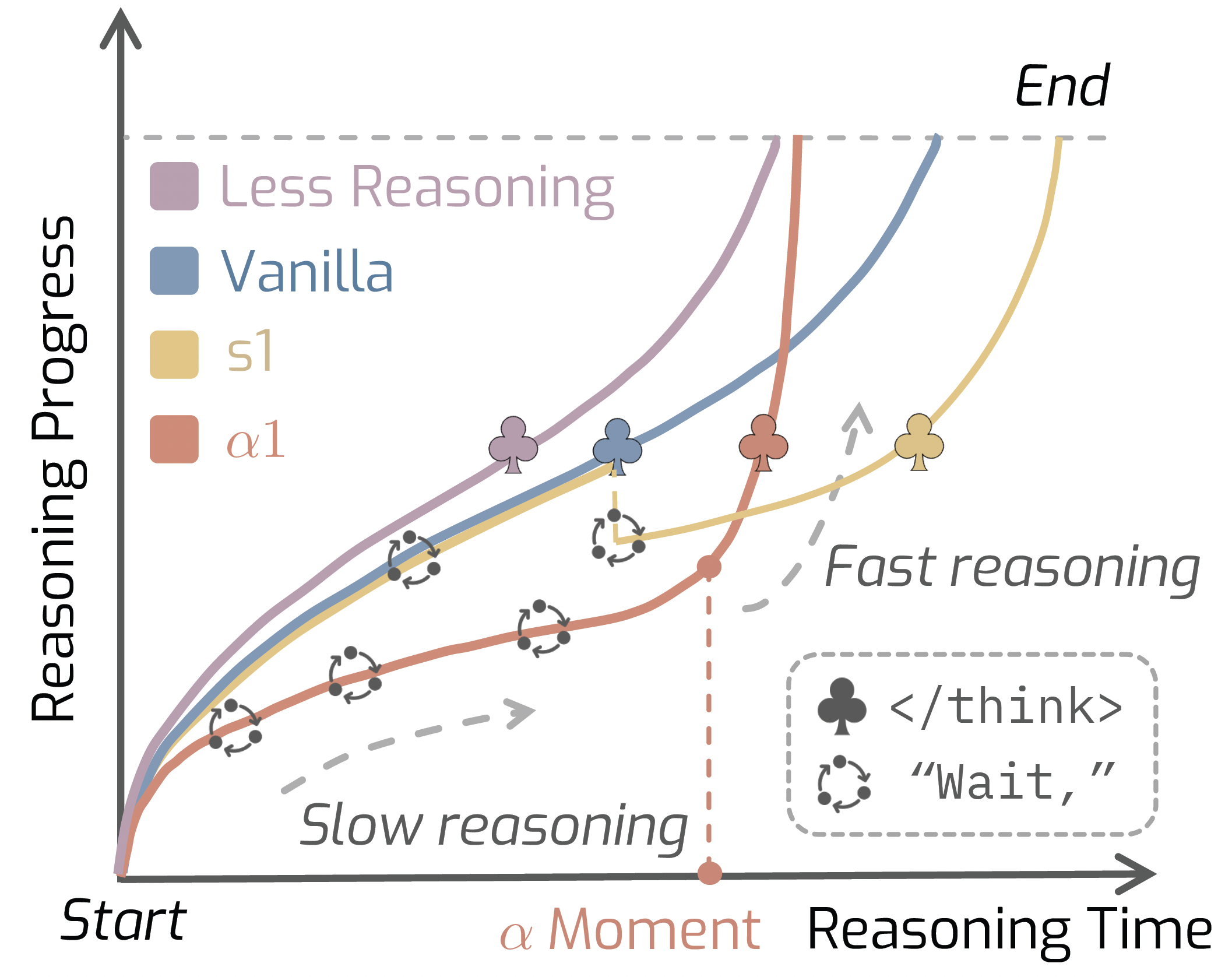
AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
Junyu Zhang*, Runpei Dong*, Han Wang, Xuying Ning, Haoran Geng, Peihao Li, Xialin He, Yutong Bai, Jitendra Malik, Saurabh Gupta, Huan Zhang
EMNLP2025
A test-time framework that controls reasoning speed of large models using a universal alpha parameter.

Generalizable Humanoid Manipulation with Improved 3D Diffusion Policies
Yanjie Ze, Zixuan Chen, Wenhao Wang, Tianyi Chen, Xialin He, Ying Yuan, Xue Bin Peng, Jiajun Wu
IROS2025 (Oral)
Improved 3D Diffusion Policy (iDP3) enables humanoid robots to perform autonomous tasks using egocentric 3D visual representations.