Xialin He (何夏麟)I'm a 2nd year Ph.D. student in Computer Science at University of Illinois Urbana-Champaign supervised by Prof. Saurabh Gupta. Before that, I earned my bachelor degree at ACM Honors Class, Shanghai Jiao Tong University and I was privileged to delve into the application of Reinforcement Learning in Quadruped Robot's locomotion while collaborating with the SJTU APEX lab under the guidance of Prof. Weinan Zhang. During my senior year, I am fortunate to work with Prof. Xiaolong Wang at UCSD Wang Lab as a research intern. During my time there, I also have the opportunity to collaborate closely with Prof. David Held. My research interests lie in Reinforcement Learning, Robot Learning, Computer Vision and Control theory. If you are interested in my work, feel free to to contact me for further discussions or potential collaborations. |


|

ULTRA: Unified Multimodal Control for Autonomous Humanoid Whole-Body Loco-Manipulation
arXiv2026
We present ULTRA, a unified framework for autonomous humanoid whole-body loco-manipulation. ULTRA combines physics-driven motion retargeting with a multimodal controller for both reference tracking and goal-conditioned autonomous control from egocentric perception.

Learning Getting-Up Policies for Real-World Humanoid Robots
RSS2025
We proposes a learning framework for humanoid fall recovery. The method has two stages: first, discovering getting-up trajectories, then refining them for smoothness and robustness. The approach is successfully tested on a real G1 humanoid robot.

Learning Smooth Humanoid Locomotion through Lipschitz-Constrained Policies
IROS2025 (Oral)
We introduce Lipschitz-Constrained Policies (LCP), a method for achieving smooth locomotion in legged robots by enforcing a Lipschitz constraint on the policy. LCP eliminates the need for non-differentiable smoothing techniques, offering a simpler and robust solution applicable across diverse humanoid robots.

OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning
CoRL2024
We present OmniH2O (Omni Human-to-Humanoid), a learning-based system for whole-body humanoid teleoperation and autonomy. Using kinematic pose as a universal control interface, OmniH2O enables various ways for a human to control a full-sized humanoid with dexterous hands and also enables full autonomy by learning from teleoperated demonstrations or integrating with frontier models such as GPT-4o

Visual Manipulation with Legs
CoRL2024
We propose a system that enables quadruped to manipulate objects with legs. We use reinforcement learning to train a policy to interact with the object based on point cloud observations, which demonstrates advanced manipulation skills with legs that has not been shown in previous work.

Learning Humanoid End-Effector Control for Open-Vocabulary Visual Loco-Manipulation
Arxiv2026
HERO enables visual loco-manipulation of arbitrary objects with humanoid robots. It combines open-vocabulary large vision models with a residual-aware end-effector tracking controller trained in simulation.

InterPrior: Scaling Generative Control for Physics-Based Human-Object Interactions
CVPR2026
InterPrior learns a scalable generative controller for humanoid human–object interactions. It distills large-scale imitation into a goal-conditioned latent policy, then improves generalization via physics-based augmentation and RL finetuning. The resulting motion prior enables robust loco-manipulation under unseen goals and initializations.
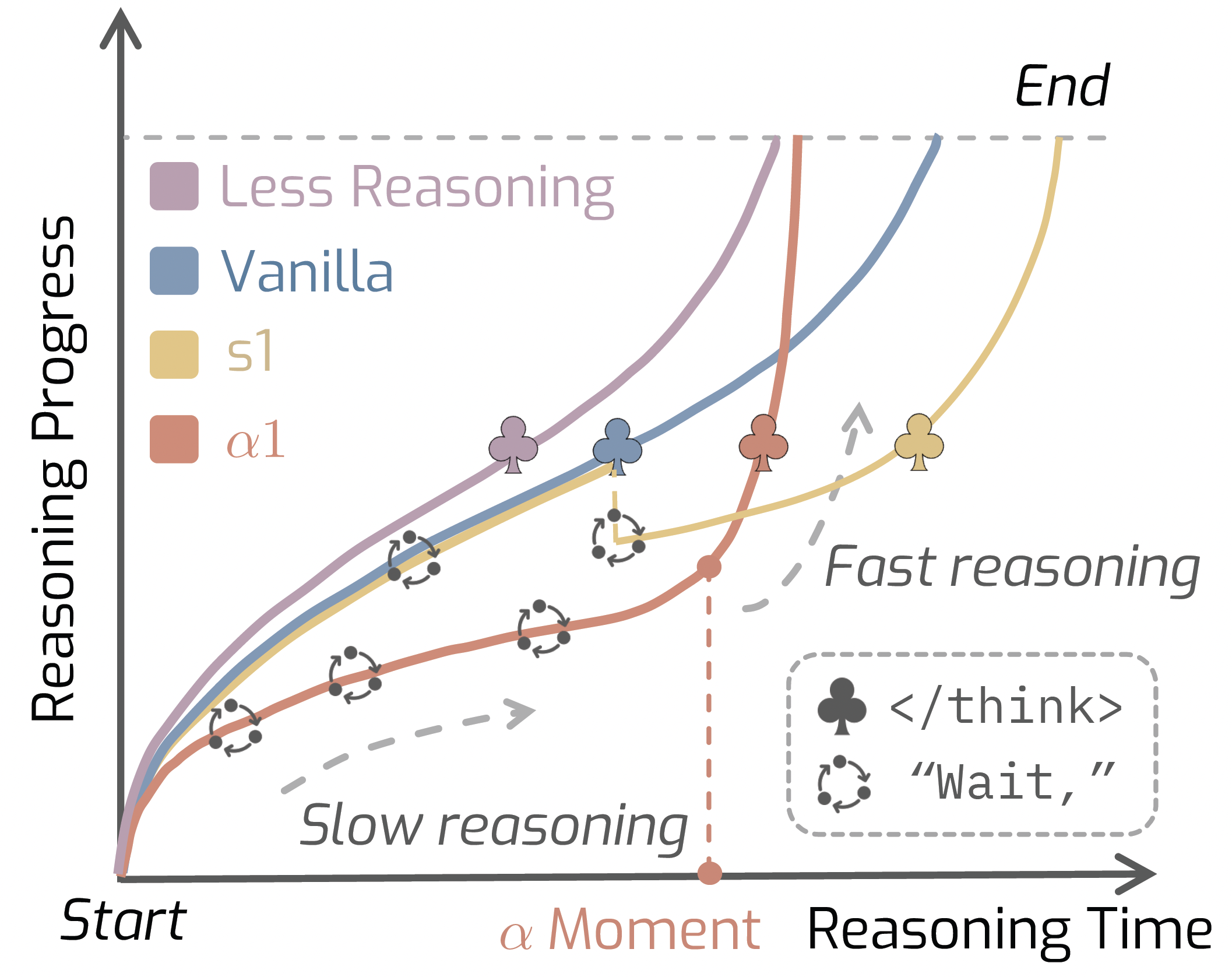
AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
EMNLP2025
This paper introduces AlphaOne, a test-time framework that controls the reasoning speed of large models using a universal α parameter. It gradually inserts “slow thinking” steps before α and then switches to fast reasoning after α. AlphaOne improves both reasoning quality and efficiency across math, coding, and science tasks.

SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
NeurIPS2025 (Spotlight)
This paper proposes semantic orientation, using natural language to describe object orientations intuitively. The authors built OrienText300K, a dataset of 3D models with semantic annotations. Integrating this into a VLM system improves robotic manipulation, achieving 48.7% accuracy on Open6DOR and 74.9% on SIMPLER.

Generalizable Humanoid Manipulation with Improved 3D Diffusion Policies
IROS2025 (Oral)
We developed the Improved 3D Diffusion Policy (iDP3), a 3D visuomotor policy that enables humanoid robots to perform autonomous tasks in varied real-world settings. Unlike traditional models, iDP3 operates without the need for camera calibration or point-cloud segmentation by utilizing egocentric 3D visual representations. This approach allows for effective performance using only lab-collected data.
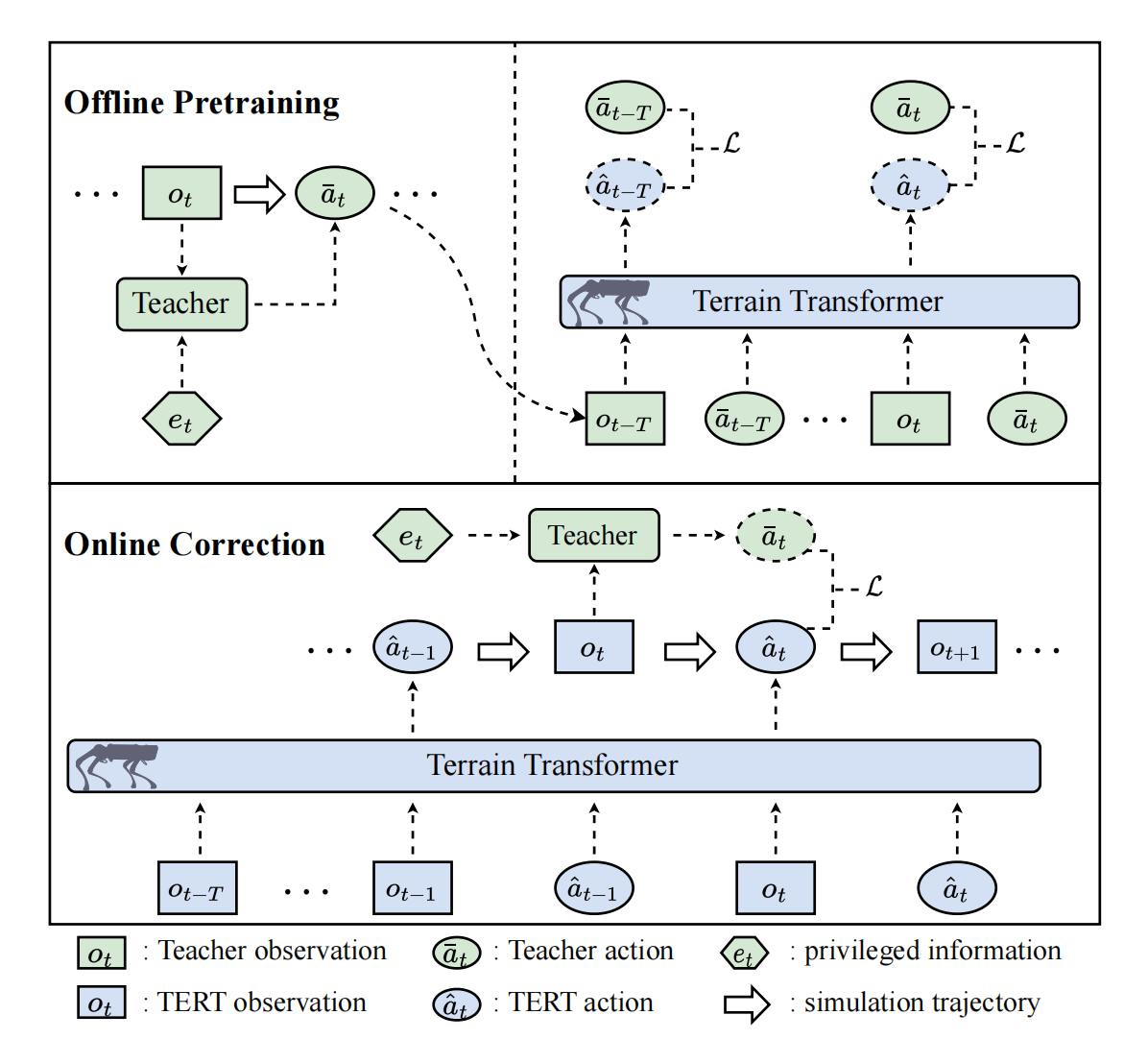
sim-to-real transfer for quadrupedal locomotion via terrain transformer
ICRA2023
we propose Terrain Transformer (TERT), a simple yet effective method to leverage Transformer for quadrupedal locomotion over multiple terrains, including a two-stage training framework to incorporate Transformer with privileged learning.
Education

University of Illinois Urbana-Champaign
Illinois, USAPh.D. student in Computer Science, Aug 2024 - Current

Shanghai Jiao Tong University
Shanghai, ChinaB.S. in Computer Science(ACM Honors Class), Sep 2020 - Jun 2024
|
|
|
Design and source code from Leonid Keselman |